

Policy & Stakeholder Analysis
Article
Into the jungle: best practices for open-source researchers
by Ryan Fedasiuk
The goal of this guide is to acquaint researchers and analysts with tools, resources, and best practices to ensure security when collecting or accessing open-source information.
- Open sources on the internet present numerous potential hazards both to users and the information they access. Navigating these hazards requires habitual vigilance.
- There are three main considerations when collecting open-source information online. In order of priority, they are:
- Protecting your devices, network, and files from malware.
- Archiving your sources for posterity.
- Masking your activities from intrusive onlookers.
The goal of this guide is to acquaint researchers and analysts with tools, resources, and best practices to ensure security when collecting or accessing open-source information.
The cardinal rules of open-source investigations
- Always assume the source has been compromised and could present a privacy risk.
- Always stay connected to a VPN.
- Never download files locally.
- Whenever possible, access only the cached or archived versions of web pages.
- Whenever appropriate, archive sources immediately.
- Whenever in doubt, scan before you click.
Resources, tools, and best practices
1. VPNs
A virtual private network (VPN) can secure your network by masking your internet protocol (IP) address and encrypting information that is transmitted from your device. Most VPN services will let you select a server through which to route internet traffic. This has the added benefit of camouflaging your IP address. For a faster connection, choose a server located near you. For a slower connection likely to raise fewer eyebrows, choose a connection based near the entity that you are researching. For China, that might be Hong Kong, Taiwan, or Singapore—or, use a service that allows you to tunnel directly beneath the Great Firewall. For Russia, the Baltic states are good options. For North Korea, consider VPN servers based in Seoul.
There are many options and considerations when choosing a VPN: price, number of servers, connection speed, whether the service keeps logs of your browsing activity, and saturation—whether the government whose files you are browsing has blocked many of the service’s possible connection nodes.
2. Cached web pages
A safer way to access any web page is to access Google’s cached version of that page, rather than visiting the website directly. A cached page is a past version of the website in question, which Google’s search engine accessed and saved internally while creating search results and previews. Not every web page is cached, but you will find that most web pages have this option.
To access the cached version of a web page, either type cache:[URL] directly into your browser’s navigation bar, or click on the three dots next to a Google search result to see more information about the page:
The bottom-right corner of the ensuing pop-up will include a button that says “Cached.” Click on it to access the cached page.
The cached version of a web page will have a banner at the top that looks like this:
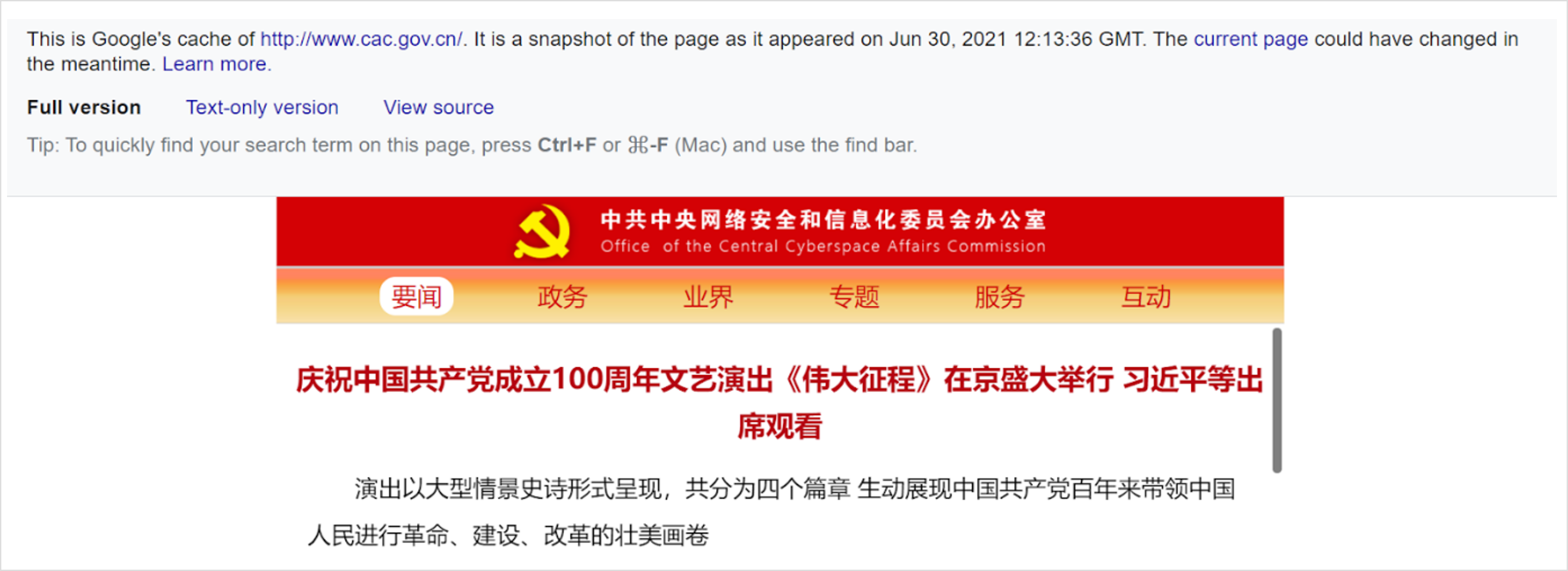
Accessing the cached version of a web page is not foolproof. It is still possible for a website owner to track which IP address is viewing a cached webpage, through certain embedded images and other elements. Accessing the text-only version of a cached page, or the HTML source code, can mitigate some of these risks, and will allow you to more quickly find information on web pages that are slow to load.
Cached web pages are especially useful for previewing documents that you would otherwise have to download directly onto your computer—something that you should avoid if at all possible. For example, take this .xls spreadsheet file hosted by the Cyberspace Affairs Commission of China:

Just clicking on this Google search result would normally result in the file being automatically downloaded to your computer—a disaster. Grappling with auto-download links is a never-ending challenge when collecting open-source information from foreign websites.
A safer (and faster) way of getting at the information is to access the cached version of the web page that is hosting the file. Rather than downloading something and opening it in Excel, Google’s cache transforms it into a web page that you can view in your browser:
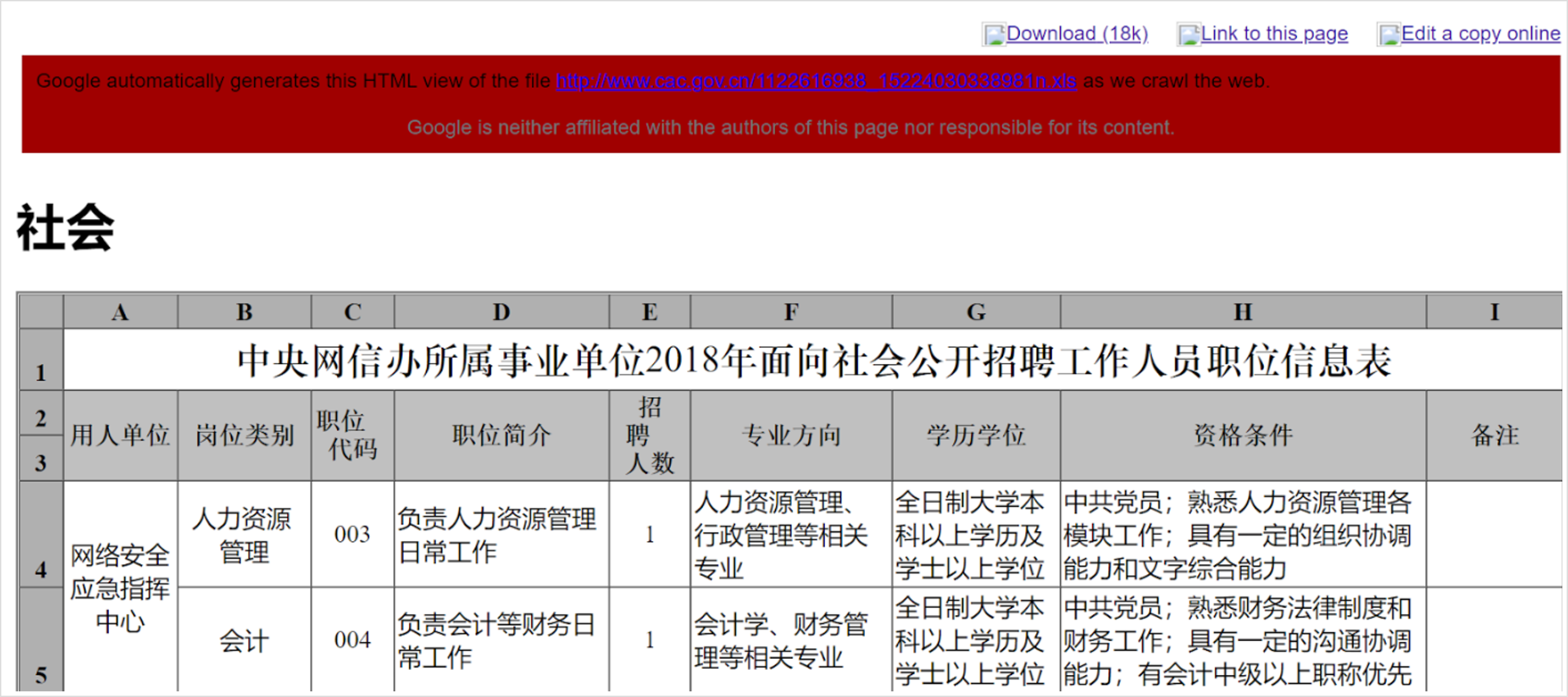
This strategy works for all common file types: .doc, .pdf, .xls, and .xlsx, among others, but will sometimes cause errors in file formatting (especially PDFs).
3. Archive services
Archiving sources is incredibly important. Within days or even hours of publishing research, sources of information frequently disappear, and original website links are frequently broken. But there are several reasons why you might want to archive a website, beyond ensuring future access to the material:
Archive services can serve a similar function to a cached web page, allowing you to view a safer version of the page. (It is also possible to archive a Google-cached web page, rather than the original source, for layered protection.)
Some archive services, like the Wayback Machine (discussed below), will tell you if someone else has already archived the page, which can be useful to know.
Some archive services will generate unique links and display the exact time stamps for when they were generated. This can be helpful in plagiarism disputes and/or tracking project timelines.
In particular, two free archiving services are embraced by the open-source community. These include:
- The Internet Archive (Wayback Machine): https://web.archive.org/save/
- Archive Today: https://archive.vn/
- It is often worth archiving particularly valuable documents across more than one archive service.
Please note that most archive services will “ping” the website with a U.S.-based IP address. This can ruin your attempts to remain stealthy, for example, with a China- or Russia-based VPN. Please also note it may be possible for website owners to retroactively break archive links you have already established. For these reasons, web-based digital archive services may not always be the best option.
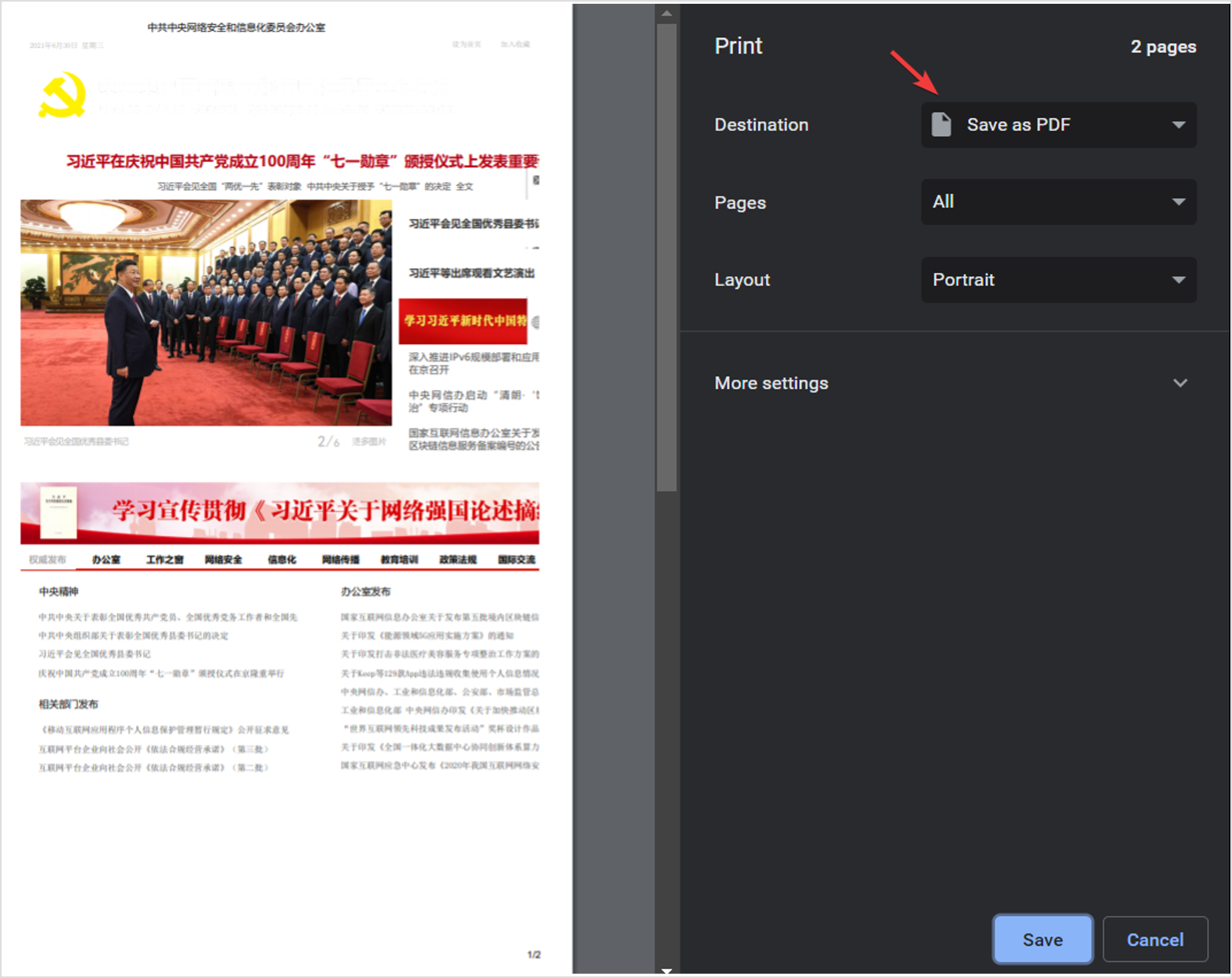
To maintain maximum privacy, security, and long-term access, it is often worthwhile to save local copies of web pages as PDFs to your computer, then upload them to cloud storage or an external hard drive. This is not the same thing as downloading a PDF from the website itself—which you should avoid if at all possible. Rather, when you are viewing a web page, follow these steps:
- First, attempt to “print” the web page by opening the print interface (press CTRL+P on a PC; CMD+P on a Mac).
- Then, instead of actually printing it out, change the destination to “Save as PDF.”
- Finally, consider duplicating the saved file to external flash drives or uploading it to a secure web cloud like Google Drive.
4. URL and file scanners
Sometimes, there will be a potentially valuable source of information that resists archiving and has no cached web page. It’s a gamble to directly access these kinds of links. But you can exercise due diligence: Whenever in doubt, scan before you click.
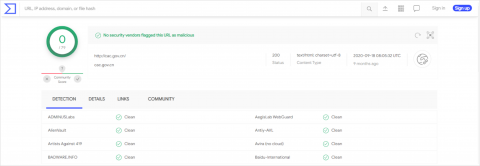
VirusTotal is a free service that scans files and URLs for malware by checking them against dozens of antivirus software services, including well-known consumer brands like AVG, BitDefender, and Kaspersky.
VirusTotal collects information about the files and URLs uploaded to its database. It is a testing platform for antivirus services. It has access to 79+ antivirus services because it provides diagnostic information to improve antivirus products from the scans that users generate. It does not require users to have an account.
5. Browser sandbox
If you are sitting down for an extended session of information-hunting, it is best to do all of your searching inside a virtual sandbox (or virtual machine, VM). There are several applications that can create a firewall around programs and applications you choose to run, such as web browsers like Google Chrome and Firefox.
A web browser session run inside the sandbox will close when the sandbox is closed. Any files downloaded from the browser will remain inside the sandbox, and can be wiped when the sandbox is closed, without being saved to your actual computer. You can still give permission to transfer individual files out of the sandbox.
There are different sandbox options available for PC or Mac users, but many are free, open-source, and relatively lightweight applications. A popular virtual sandbox application for PC users is Sandboxie. For Mac users, consider Oracle’s VirtualBox.
6. Antivirus software
If you are conducting open-source research, it behooves you to have a subscription to high-quality antivirus software. However, if you do not already have antivirus on your computer, there are some free options worth downloading and running regularly:
- Malwarebytes offers free, relatively lightweight, on-demand malware scans. It can be run in conjunction with other antivirus software products.
- Bitdefender is often cited as a high-quality, free antivirus software. And free trials are offered by paid subscription sources including Norton, McAfee, AVG and Kaspersky.
Conclusion
If at any point you break one of the six cardinal rules outlined in this guide, or accidentally click on an auto-download link, it’s worth running a quick Malwarebytes scan. But remember—the best practice when conducting open-source investigations is to assume compromise. If a state wants to track your browsing and research activity, it will surely be able to do so.
Governments and media publications everywhere are starting to embrace the value of open-source investigations. Even in relatively closed societies, there is an unmined ocean of data capable of informing business and policy decisions. Recent studies have highlighted the utility of budget documents, purchasing orders, geospatial imagery, social media posts, government records, and elite biographies in understanding states’ geopolitical ambitions and military capabilities. Armed with these tips and tricks, where will you venture next?
This guide was initially published by Ryan Fedasiuk at the Center for Security and Emerging Technology (CSET).
Ryan Fedasiuk
Adjunct Fellow at the Center for a New American Security (CNAS)

Ryan Fedasiuk is an Adjunct Fellow on leave from the Center for a New American Security (CNAS). Ryan previously worked as a Research Analyst at the Center for Security and Emerging Technology (CSET), where his portfolio spanned military applications of artificial intelligence, U.S. security posture in East Asia, and China’s influence operations and efforts to acquire foreign technology. He has also served as an advisor for SandboxAQ, a quantum technology company; and worked at the Center for Strategic and International Studies, Arms Control Association, and Council on Foreign Relations. Ryan holds an M.A. in Security Studies from Georgetown University, where he also studied Chinese. He received his B.A. in International Studies and a minor in Russian from American University.
